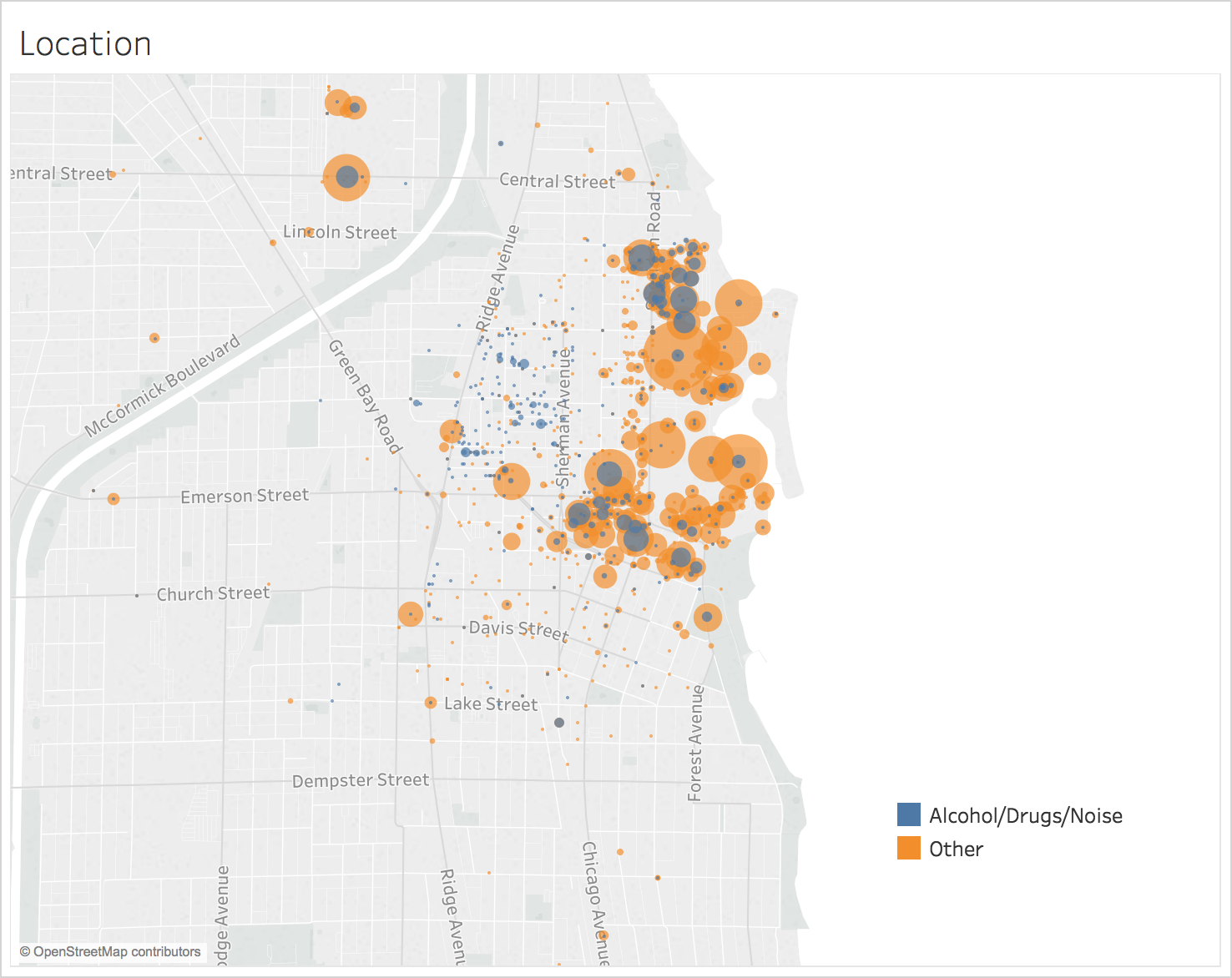
NU Blotter's task is to predict the incident type of Northwestern Campus blotter entries using the time and location of the incident. This simulates what a real-time system to classify 911 calls would have to do. This kind of system would be useful to the police officers because it could allow them to respond to 911 calls faster and with more specificity. In addition, this model can be used to better understand the patterns in police incidents around campus. In particular, better understanding of crimes commonly associated with students, such as alcohol law violations and noise complaints, could help improve relations between Northwestern students and Evanston residents.
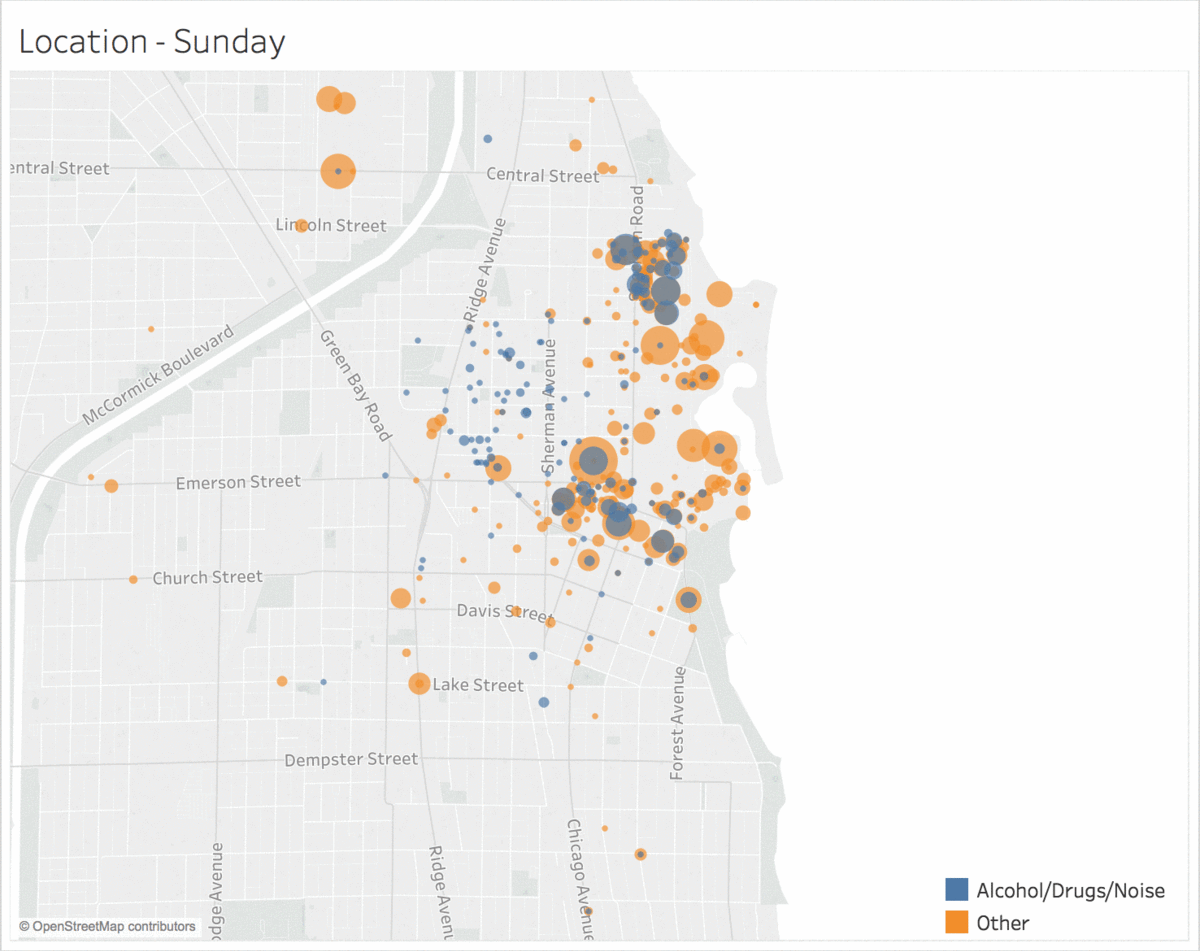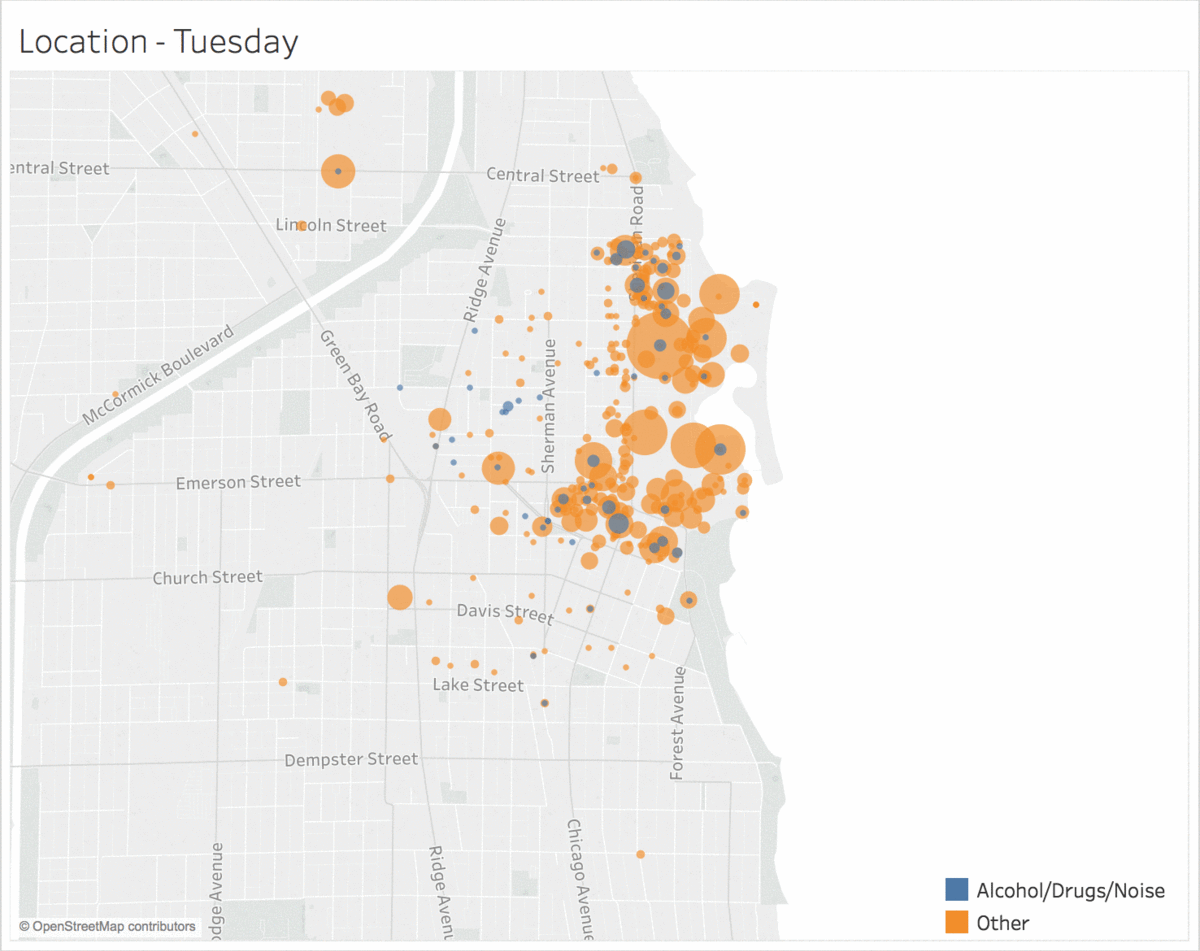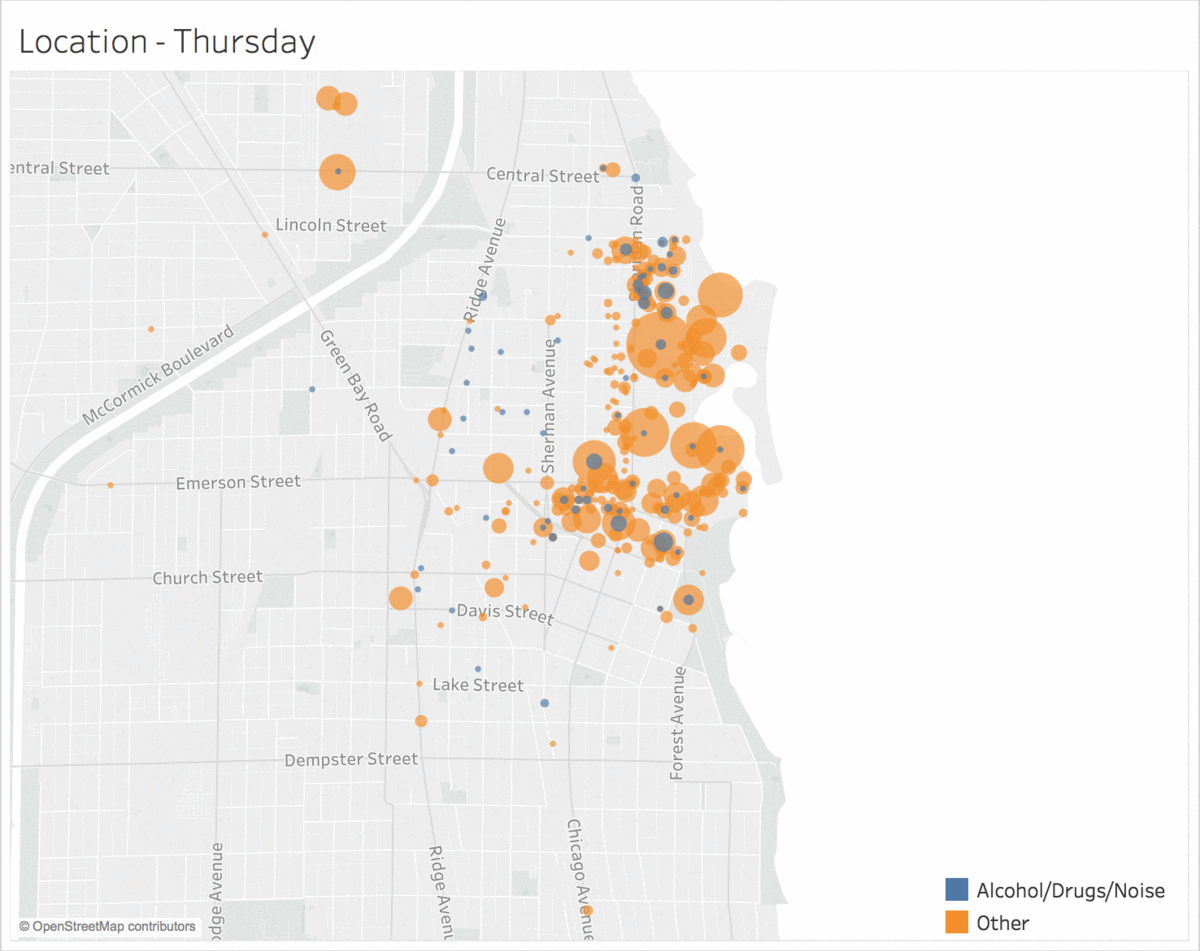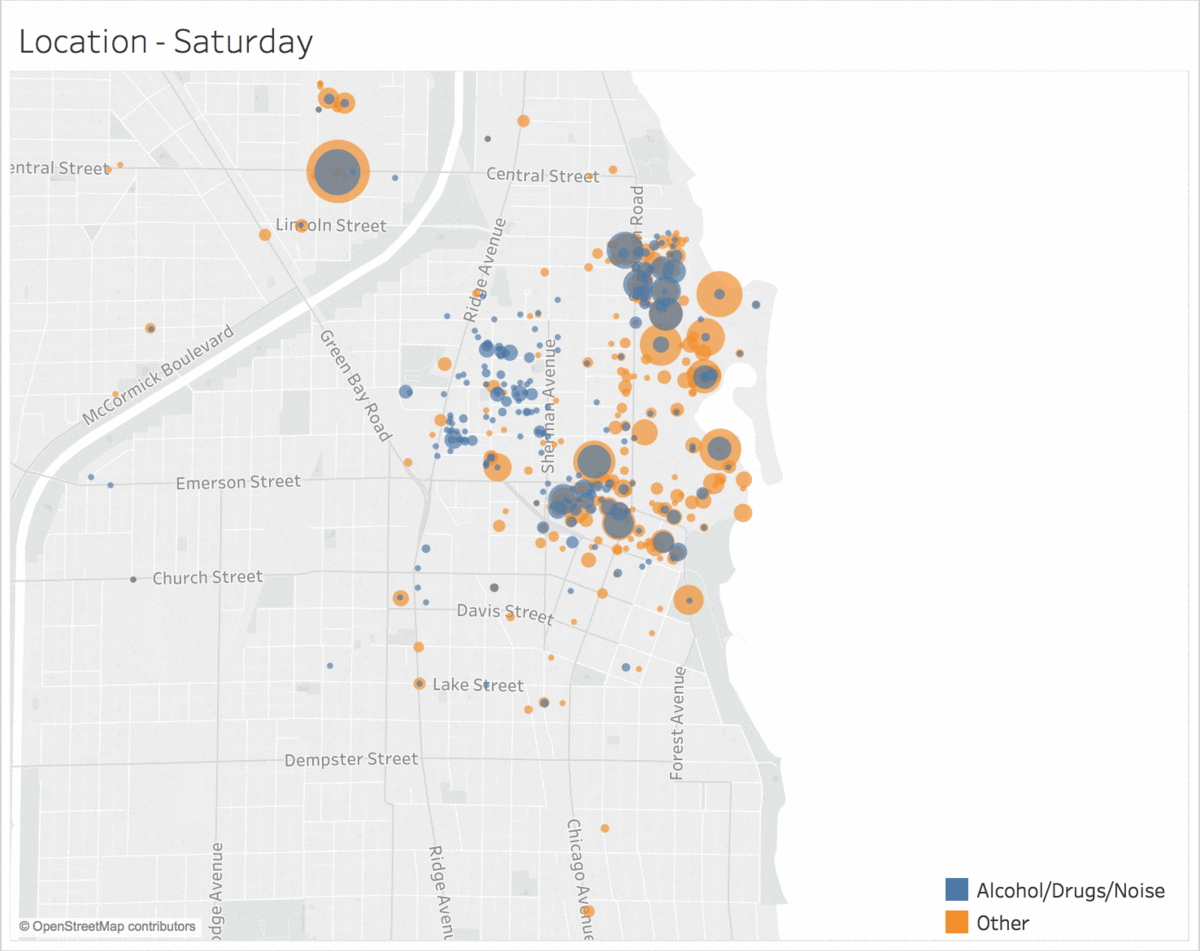
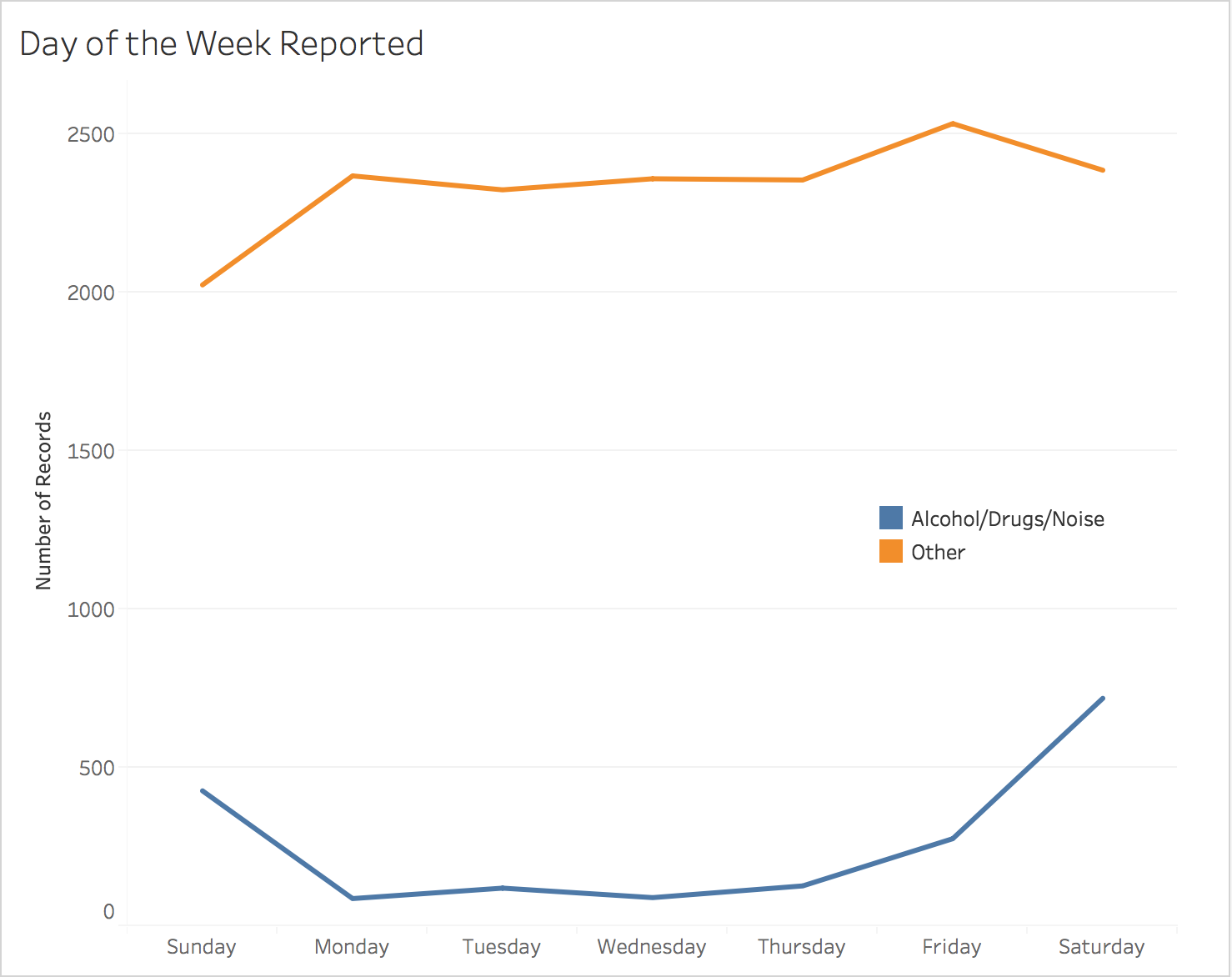
Location of Incidents by Day of the Week
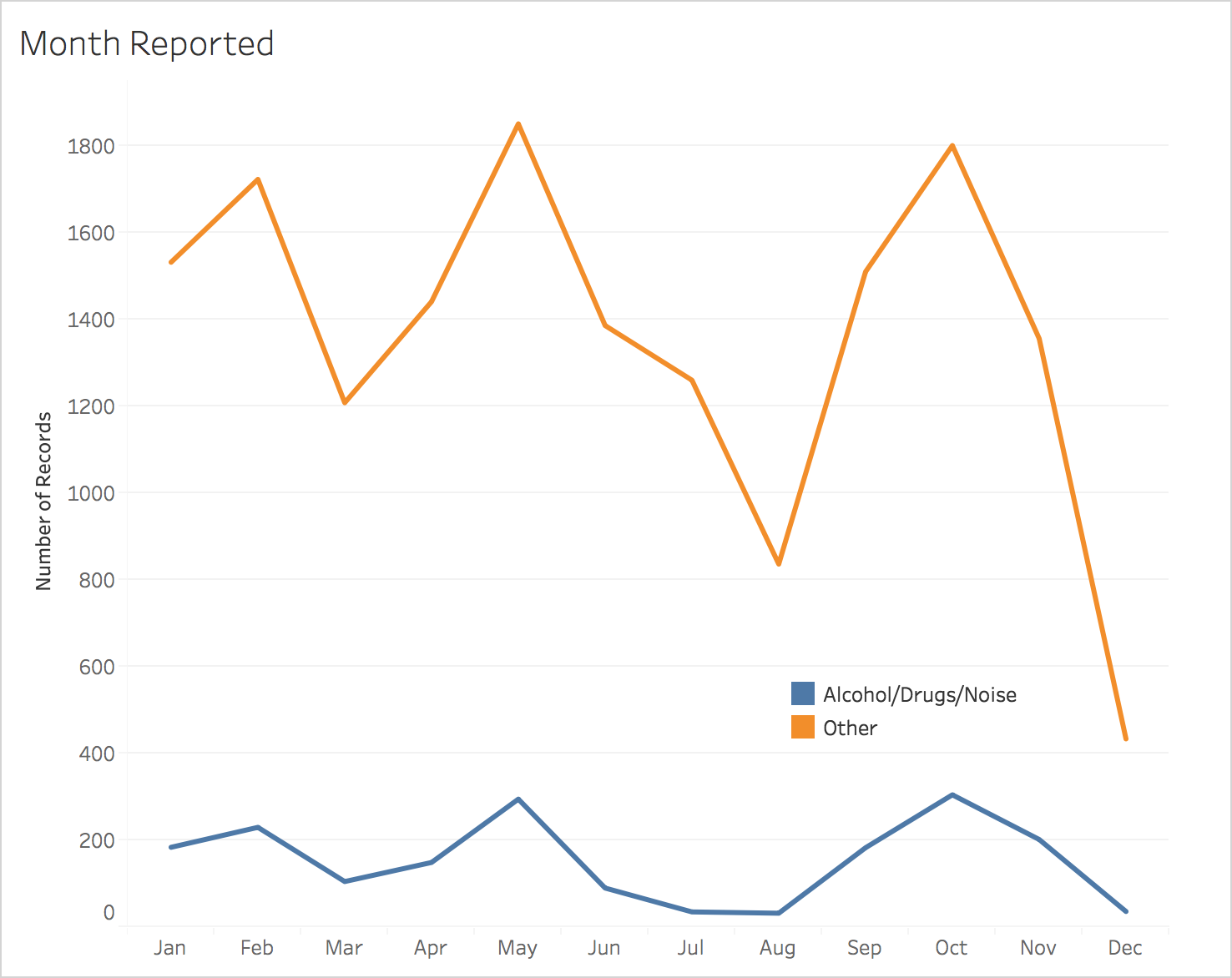
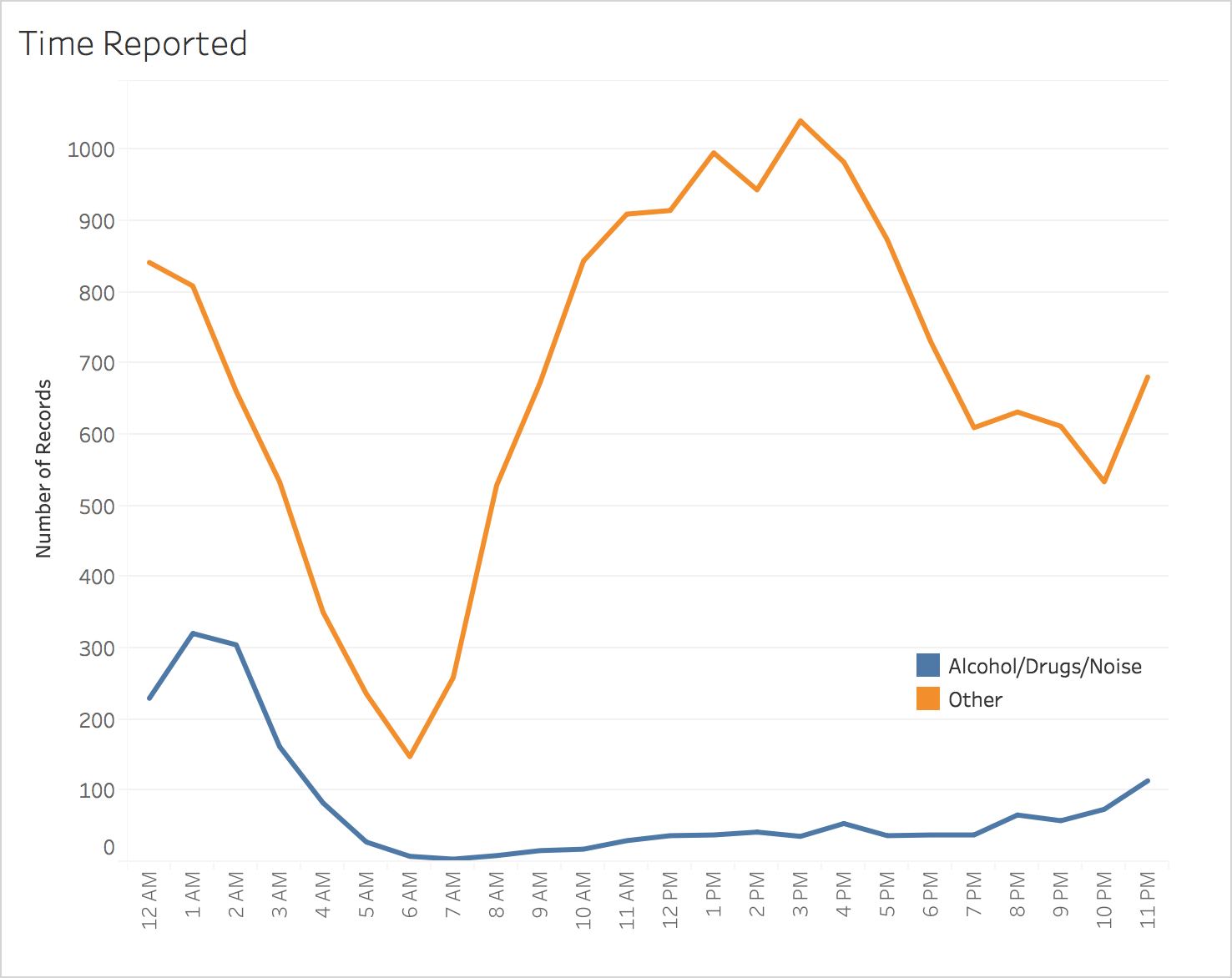
Incidents of the same type tend to be clustered in location and time.
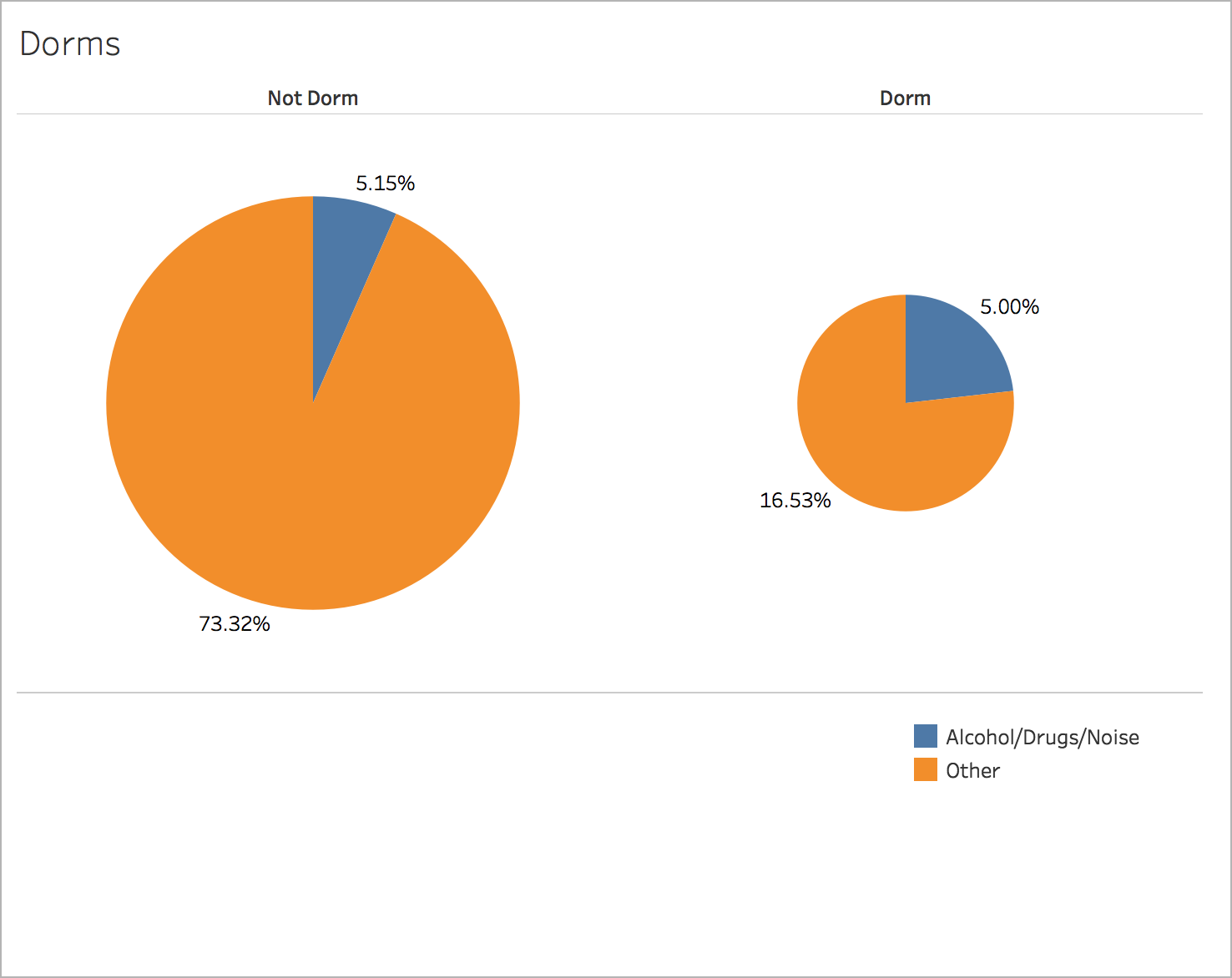
NU Blotter uses the algorithm 1-nearest neighbor to classify incidents into two classes: Alcohol/Drugs/Noise and Other. The features it uses to predict these classes are month, day of the week, time, latitude, longitude, and whether the address is a dorm. Using these features, the model is able to predict whether the incident type is Alcohol/Drugs/Noise or not with 87.70% accuracy, although this metric is not necessarily ideal (see Model Selection). Using F1 score as a metric, 1-nearest neighbor strongly outperformed the baseline algorithms, as well as decision trees and logistic regression.